The Central Limit Theorem is one of those spooky math results that probably keep mathematicians awake on full moon nights. This post will try and illustrate the central results of the theorem so that some of us slumbering mortals might also lose some sleep occasionally.
In essence the theorem states that given a bunch of numbers (aka the Population), if you randomly select small - but big enough - groups of numbers (aka sample) from it and add the numbers in these samples together; the group of numbers produced as a result of this addition will always be distributed in a specific pattern called the normal distribution. The addition component is very important, it’s not enough that you select samples from the population, you must add the data within the samples for the CLT to hold. This also means that whenever you are dealing with some data that could possibly be expressed as the result of randomly summing other quantities you can apply the CLT.
The cool part here is that even though you don’t know anything about the original population, you can find it’s mean and variance if you take a set of large enough samples.
Now if instead of just adding the numbers inside the samples, we calculate their average or mean, some more interesting results can be obtained. Lets also introduce some notation to make the textual statements clearer.
Population mean = $ \mu_P $, variance = $ \sigma_P $ (aka sample distribution)
Set of sample means = (aka sampling distribution)
Mean of set of sample means = $\mu_X$, variance = $ \sigma_X$
- The mean ($ \mu_X $) of the set of sample means will approach the actual mean of the population
- The variance ($ \sigma_X $) of this mean is approximately equal to the population variance divided by
N($ \sigma_P/N $), whereNis the size of each sample (i.e. the count of numbers in each sample)
More about N
The sample size N is rather important, it must be reasonably big for the CLT to hold. If it’s too small, then there’s not going to be any soup for you. The right size of N depends on the original sample population. If the original population is a decent symmetric one then - according to the math gurus - a value of N <= 30 is good enough. However if the original population is skewed, then you might need higher values of N. For example imagine an impulse function - a value of K at one point and 0 elsewhere. You might need a large sample from the population to end up with a sample that has K inside it.
Proof or maybe not
Since the proof of a pudding is in the coding and not in the deriving, let try some experiments.
The below script calculates the Population and Sample statistics based on CLT, and plots a histogram of the sample means for a given population function. Feel free to play around with different settings for N and P. I use N = 40 as the threshold in the script, but 30 should also yield similar results.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 | |
A sinusoidal population
The population numbers are extracted from one period of the sin() function. Running the script produces the following result
1 2 | |
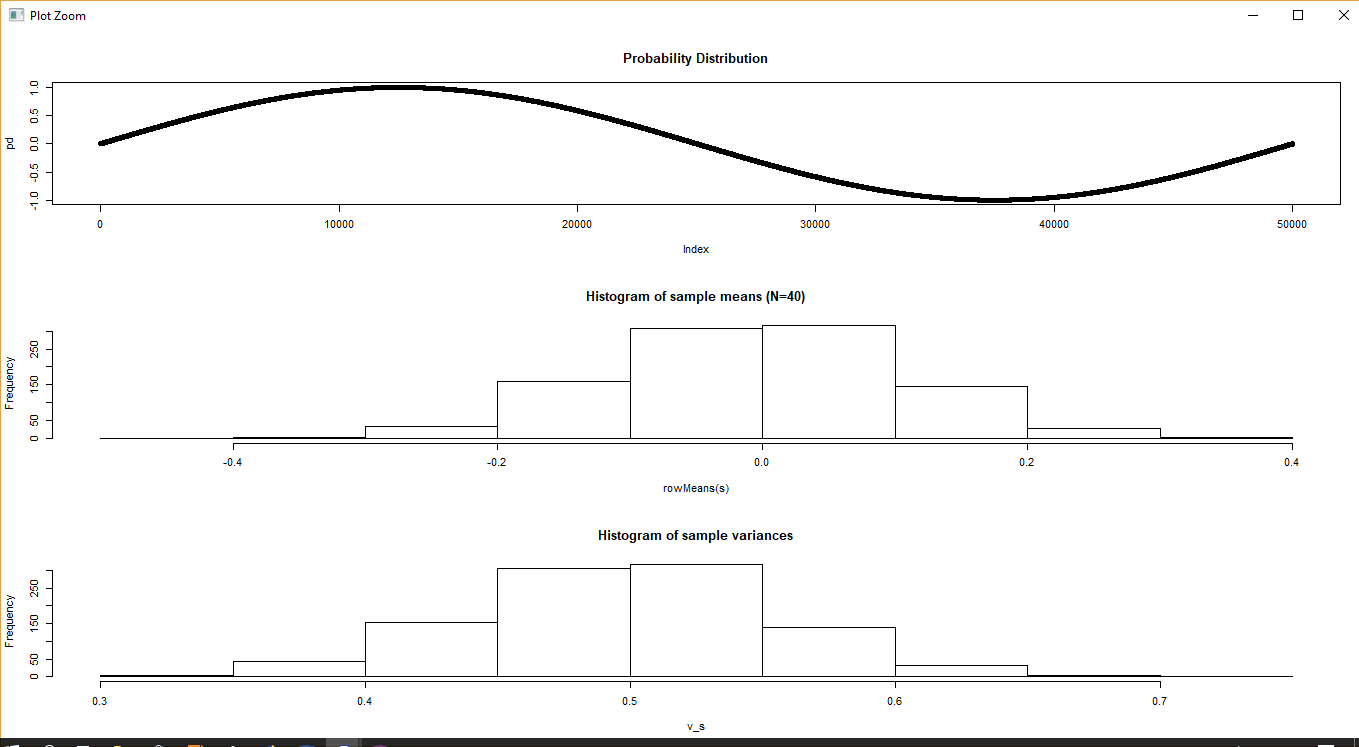
Since the function is nice and symmetric, a value of N=40 is more than enough to result in a sample mean that’s almost equal to the population mean, and the sample mean variance is also almost equal to that predicted by the (known) population variance.
An exponential population
This population is extracted from the exp() function.
1 2 | |

The results are not as perfect as before, but it’s still pretty close. Increasing the parameter of the exponential function from 10 to 100 will result in a plot that’s clearly not normal. Increasing N to 200 brings us closer to CLT expectations.
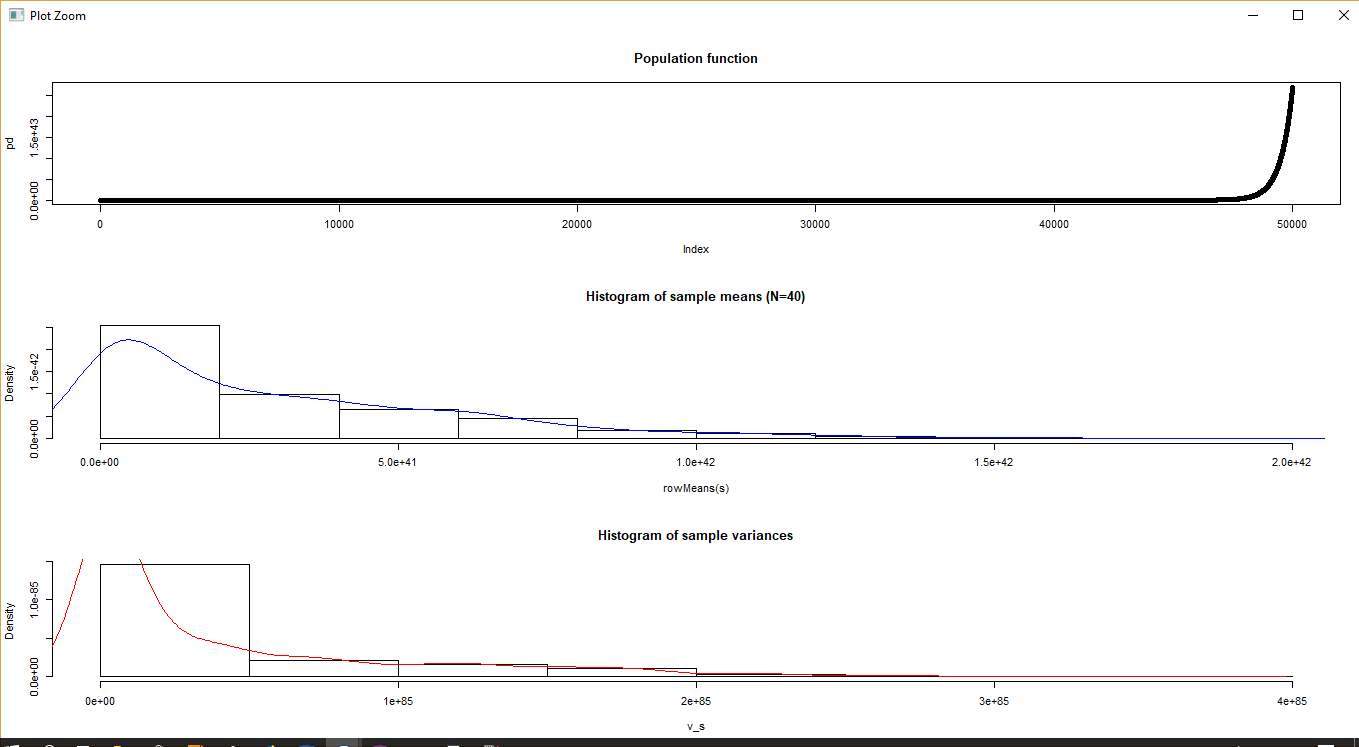
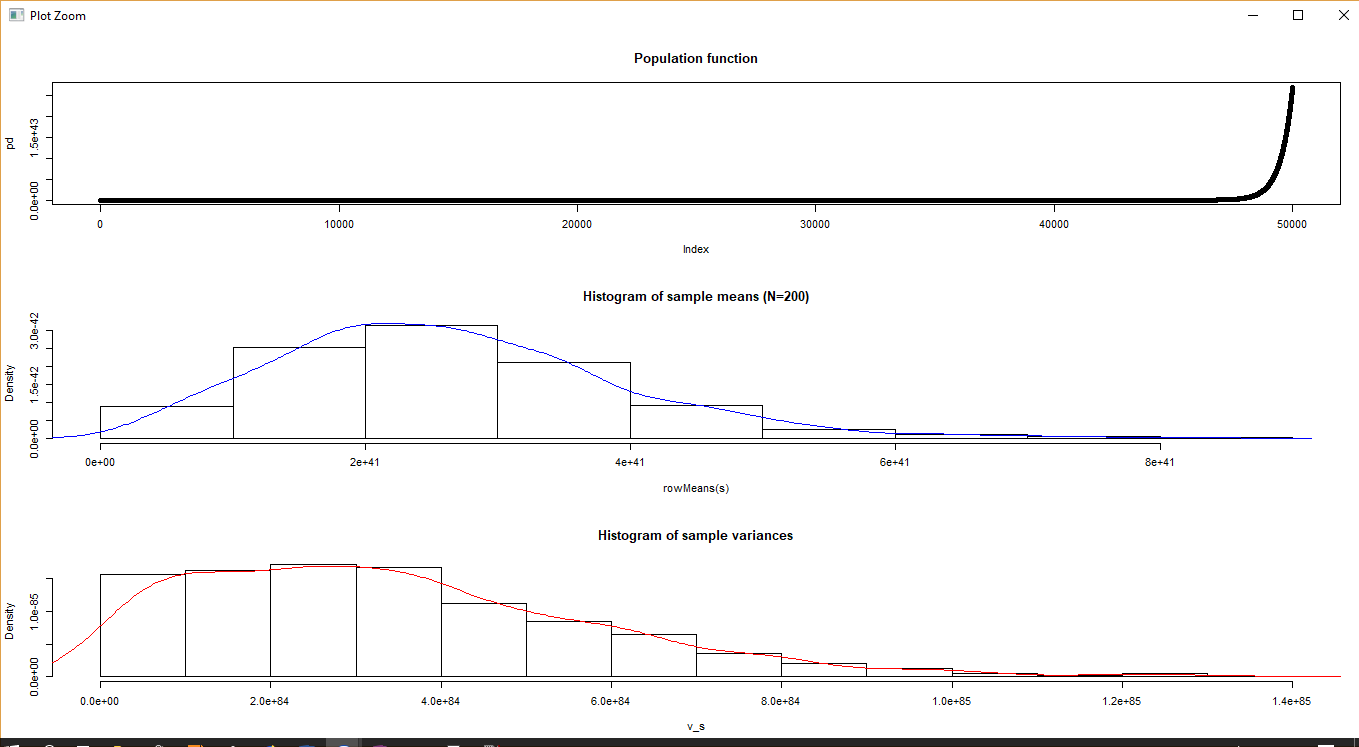
A random function
To illustrate that the CLT does not depend on the original population distribution, we set the population to be a random function. One can see that for a random data, N = 40 is pretty good.
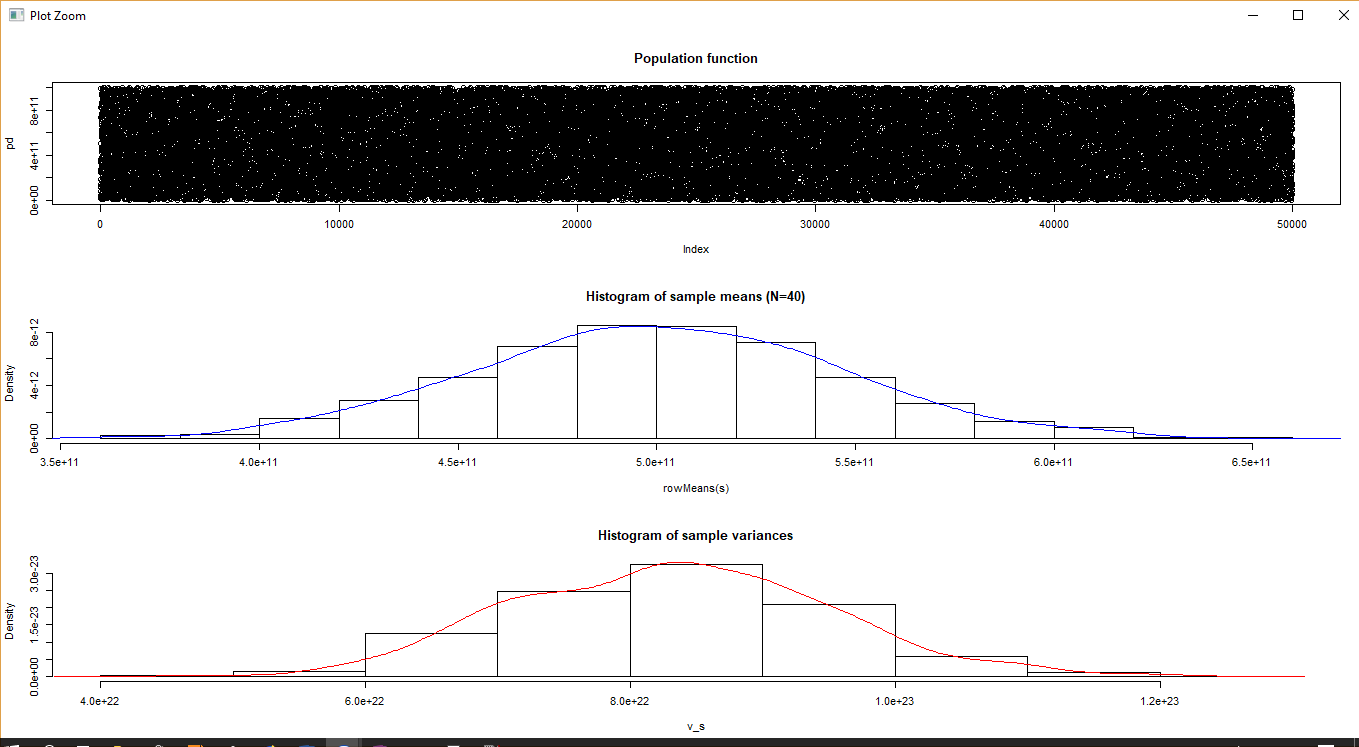
Other considerations
Sampling with and without replacement
The examples are all based on samples taken with replacement, meaning that every sample is drawn from a population of P = 50000, and the samples taken are not deleted from the population. If you reduce the size of the population as you take samples, then the CLT formula needs a correction in the variance formula as specified here. However this can be ignored if the population size is much larger (20x) of the sample size.
Random data
It’s important that you take random data for each of the samples, otherwise you won’t get the desired results. For instance imagine that you keep on repeating the same sample of data, in this case you may never reach close to the population mean until N becomes almost as large as the population. In practice this is a difficult requirement to get right because you might unknowingly introduce biases. For example if you do an online survey as a means of sampling, you might only be targeting a certain segment (eg: tech savvy people) of the population which might invalidate your results with respect to other segments of the population.
Conclusion
That concludes the introduction to CLT. A lot of statistics tests introduce CLT using probability concepts, however CLT - as you can see - is a property of the sums of random numbers and does not require a background of probability.
All the plots I have generated show sampling distribution of variances (in addition to the mean) - this does not follow the normal distribution but instead follows the chi-squared distribution with N degrees of freedom, though to be honest, I can’t visually tell a huge difference.